MEV Workshop at SBC 23 Part 1
Summary of MEV Workshop at the Science of Blockchain Conference 2023. Videos covered are about ordering policies for MEV mitigation

Fair ordering is misguided

This talk was inspired by a number of events kind of back in February this year or some work from others
A lot of people have looked at ordering policies and kind of how to implement Fair Ordering, which usually means these First In First Out (FIFO), aka First Come, First Serve (FCFS) type mechanisms
FIFO/FCFS ordering processes transactions based solely on the time they arrive, without considering factors like transaction fees or priority.
Solana and Arbitrum use FIFO/FCFS in production, so we can look what's happening with this ordering policy
Solana (1:15)

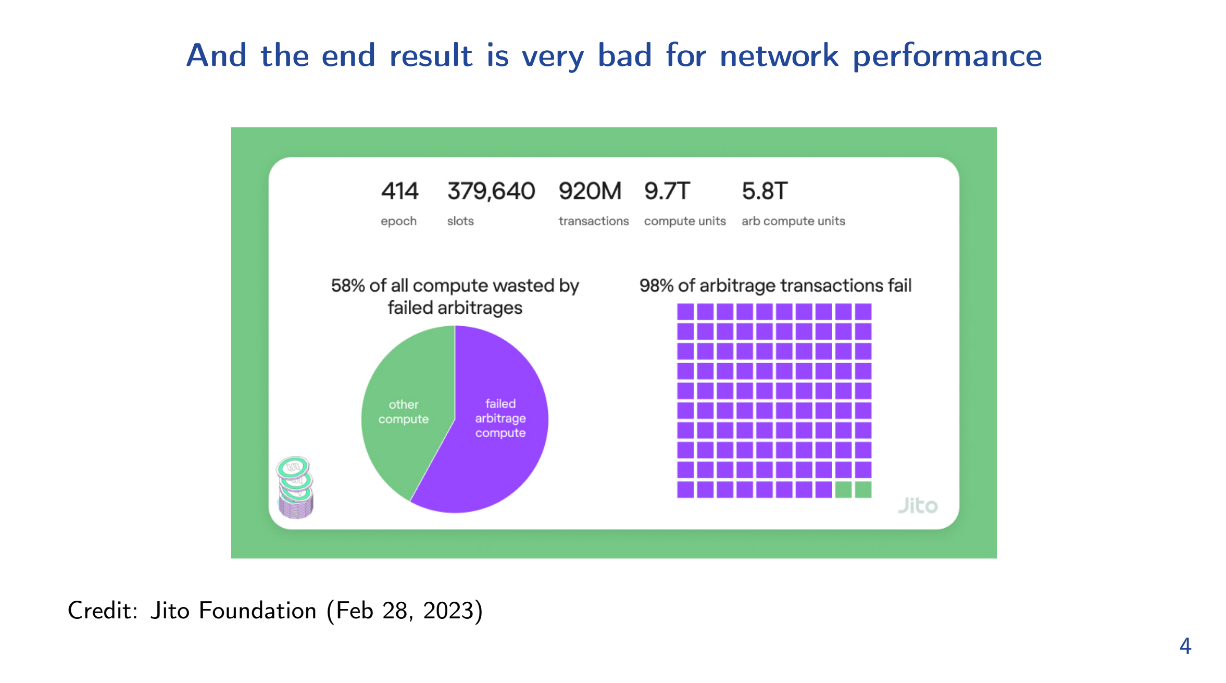
Solana without Jito effectively uses something like FIFO ordering and there's close to negligible fees. The thing is, it's a very high utility transaction to be first and only one person can get it.
Therefore, Searchers are going to end up spamming the network, trying to be the first transaction. And it hurts other users and validators, with 58% of wasted compute and 98% of Arbitrage transactions fail.
Arbitrum (2:30)
Arbitrum sequencer FIFO ordering also led to spam. The network ended up with 150,000 WebSocket connections and that was not sustainable.
Abritrum proposed a solution called "hashcash", but that was controversial at it was Proof-of-Work. Now they are moving towards priority fees instead
Conclusion (3:30)
FIFO ordering distorts market for block space by forcing regular users to bear the costs of externalities like Arbitrage spam. We need a market to allocate block space efficiently
We need a market to allocate block space
The Math model (3:45)


Theo introduces a mathematical formulation of the block building problem as an optimization model.
More specifically, this is a knapsack problem, where we must maximize net utility for our transactions with gas limit constraints
This model is a simplification, but it captures enough for our purposes
Greedy heuristic works well (6:00)


Very strictly speaking, essentially if the gas cost per unit transaction isn't too close to the limit, this means that we can fit a lot of transactions into the block.
The model shows that the greedy algorithm of taking highest utility/gas transactions first is approximately optimal for this problem.
Though not directly stated, the model demonstrates utility maximization outperforms simpler policies like FIFO for block building.
The FIFO Block (8:30)
Theo analyzes how a First In First Out (FIFO) block performs compared to an optimal utility maximizing block.

The FIFO Block is pretty simple : transactions are ordered by arrival time and added until block is full. We assume random arrival order
Because of the random arrival assumption, it's easy to calculate an upper bound on the expected total utility of the FIFO block
Calculating the "Welfare Gap"
What's the gap ? (9:30)
The "welfare gap" is defined as the utility of the optimal block minus the expected utility of the FIFO block. The goal is to show this gap is large.


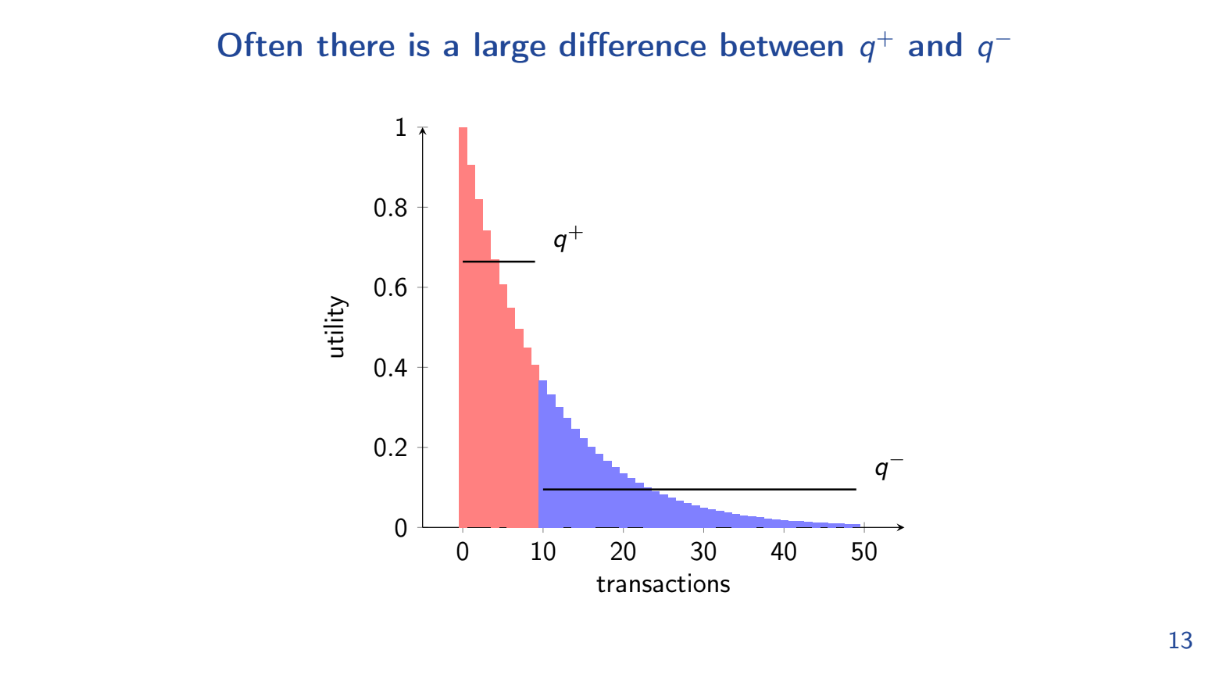
Using previous results, we can lower bound the utility of the optimal greedy block. And we just upper bounded the FIFO utility. So we can now upper bound the welfare gap using 2 bounds :
- q+ is the average utility per unit of gas for transactions in the optimal greedy block.
- q- is the average for the remaining transactions.
The gap is positive whenever q+ > q- by even a small amount. Intuitively, whenever there are some very high utility transactions, the gap will be positive and FIFO performs worse than optimal.
In practice, the gap is frequently positive because highest utility transactions (like liquidations) are picked first for the optimal block. As a result, FIFO is suboptimal
A simpler bound (11:45)

Let's try another formula for calculating the "Welfare Gap" between the optimal block and the FIFO block :
q+ > (B+ / B-) q-
- Q+ is the average utility per gas for the optimal block
- B+ is the max transaction size
- B- is the min transaction size
- Q- is the average utility per gas for remaining transactions
So whenever the above equation is true, the FIFO block performs worse than optimal.
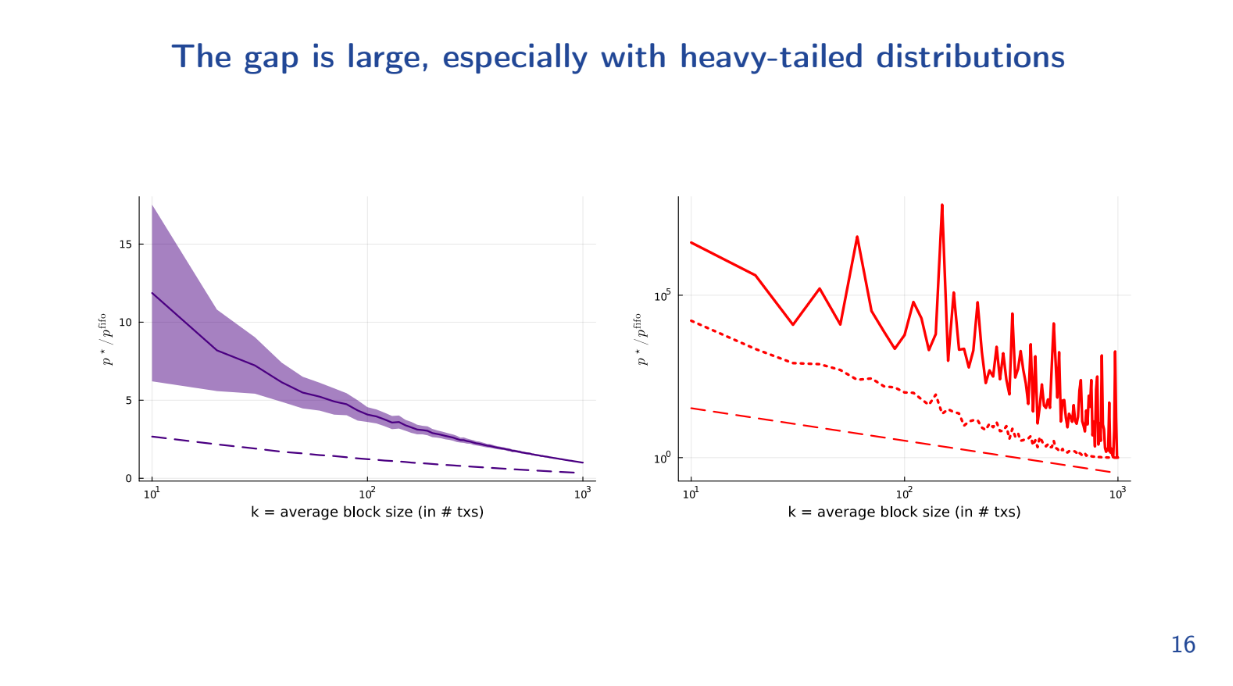
With a fast decaying distribution, the FIFO block has 2-3x lower utility than optimal, even for large blocks.
With a heavy tailed distribution (some very high utility txs), the gap is 10^5x - massive!
This causes spammers to flood the network trying to get those high utility transactions in first under FIFO, and this is not optimal
Wat do ? (14:30)

Even if you could implement FIFO type policies, there is going to be a welfare gap and that causes these benign users to pay for their externalities.
Theo outlined problems, solutions are being explored :
- One approach is better characterizing the value of transaction reordering and designing mechanisms to minimize MEV costs
- Making applications order independent also helps, so transaction order in block doesn't matter
- Developing better on-chain auction mechanisms for block space is promising
Lots of people (Flashbots, Arbitrum...) are working towards implementing policies that have sensible markets for blockspace, and some talks are dedicated to them
Q&A
Based on the analysis showing issues with FIFO/short blocks, are longer blocktimes more efficient ? (16:45)
The model doesn't address optimal block time and can't conclude anything about it. But the nice thing is these results are independent of that.
The model was just intended to show FIFO is problematic from an optimization viewpoint, regardless of blocktime.
Considering Arbitrage utility decreases if wait longer, would accounting for changing transaction utility over time affect the analysis ? (19:00)
Model doesn't account for this currently. Extending the model to account for dynamic transaction utilities is an interesting potential extension in the future.
Order Policy Enforcement
Limitations and Circumvention
Reordering transactions
The problem of state machine replication (0:00)
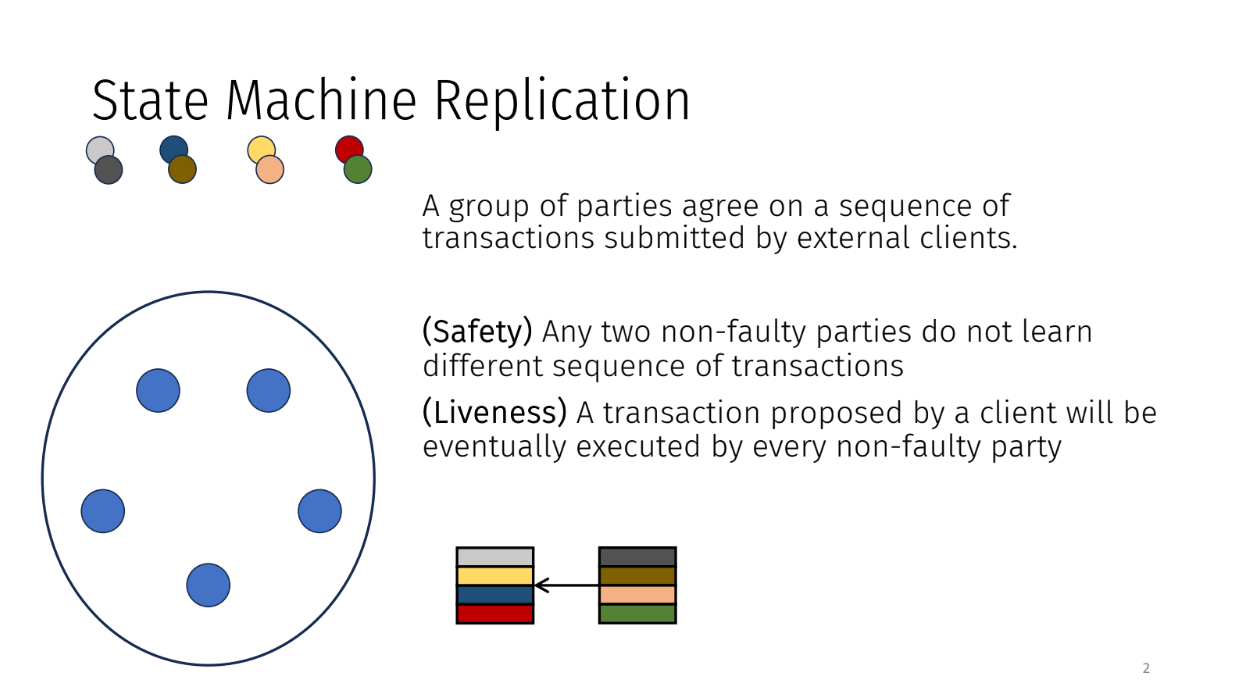
The problem of state machine replication is one where a group of parties agree on sequence of transactions submitted by external clients. There are two key properties that we're looking for :
- Safety : no disagreement on order
- Liveness : transactions eventually executed
Transaction reordering (1:00)
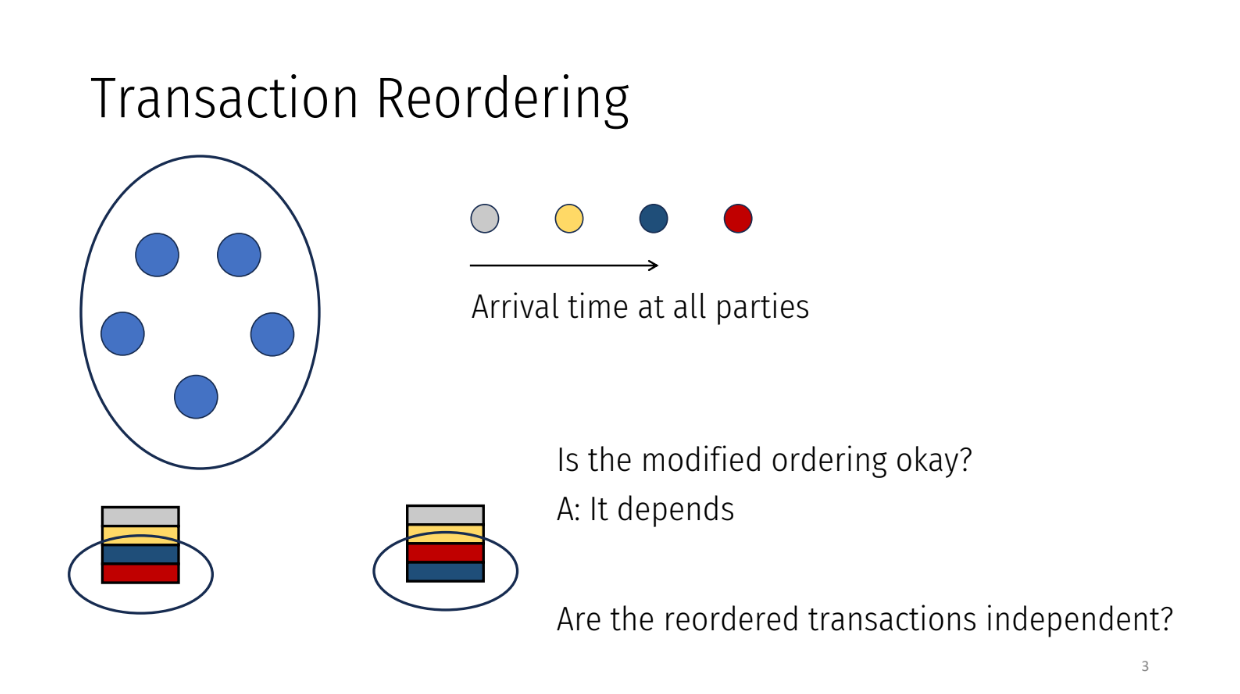
The parties receive transactions one by one over time. They group transactions into blocks and agree on an order to process each block.
The order should match the order the transactions arrived in the system. For example, if a gray transaction arrived first, a yellow second, and a blue third, then the agreed order should be gray, yellow, blue.
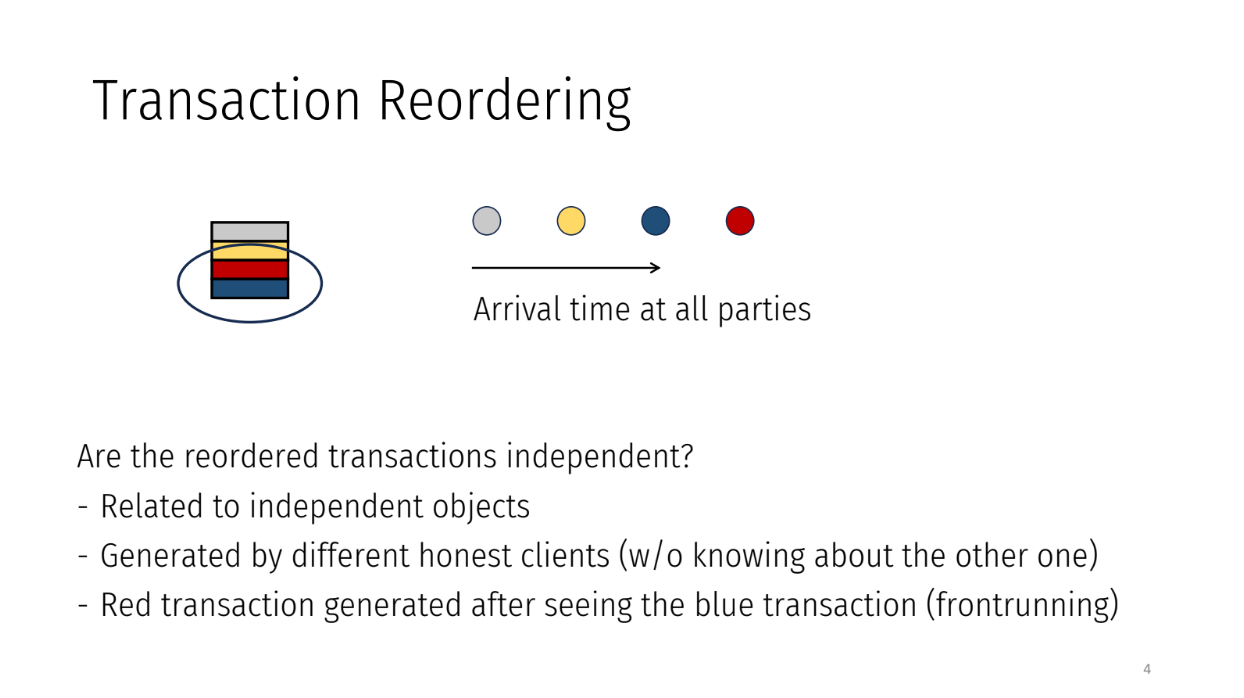
However, the parties could decide to change the order for some reason. They may put a transaction that arrived later (like red) before an earlier one (like blue).
Whether this is okay or fair depends on if the transactions are related. If two transactions are completely independent, changing the order is probably fine. But if they are related, it causes problems.

Reordering transactions is a known issue with known attacks. But there are approaches to prevent cheating by enforcing orders that match when transactions arrived. The talk will discuss solutions to this problem.
Approaches to Data-Independent Order Policy Enforcement (3:15)


Researchers have tried 2 approaches to make sure transactions are ordered fairly :
- "Order Fairness" : This orders transactions based only on when they arrive to the system. So if Transaction A arrives before Transaction B at all the parties, then A will be ordered before B. This prevents transactions from being reordered unfairly.
- "Content Oblivious Ordering" : The content of each transaction is hidden from the parties ordering them. The goal is to prevent cheating based on transaction contents. Parties can only use metadata like arrival time to order transactions.
Both try to enforce fair ordering of transactions. But do they fully prevent unfair reordering attacks ?
The concern is that both approaches rely on most parties being honest. But the reason for unfair reordering is parties want to cheat for personal gain. There is a mismatch between the threat model these protocols assume, and the real-world motivations for attacks.
Today's talk (6:00)

The key question is whether these protocols are secure when all parties are rational actors trying to maximize personal profits.
In this talk, Kartik will focus on answering this question first by analyzing existing order fairness protocols when all parties are rational, then exploring a new approach called Rational Ordering that secures ordering against rational adversaries
Create the framework
Kartik is explaining a framework that captures different protocols for fairly ordering transactions in a system. They use a specific protocol called "Threshold Encryption Content Oblivious Ordering" as an example within this framework.
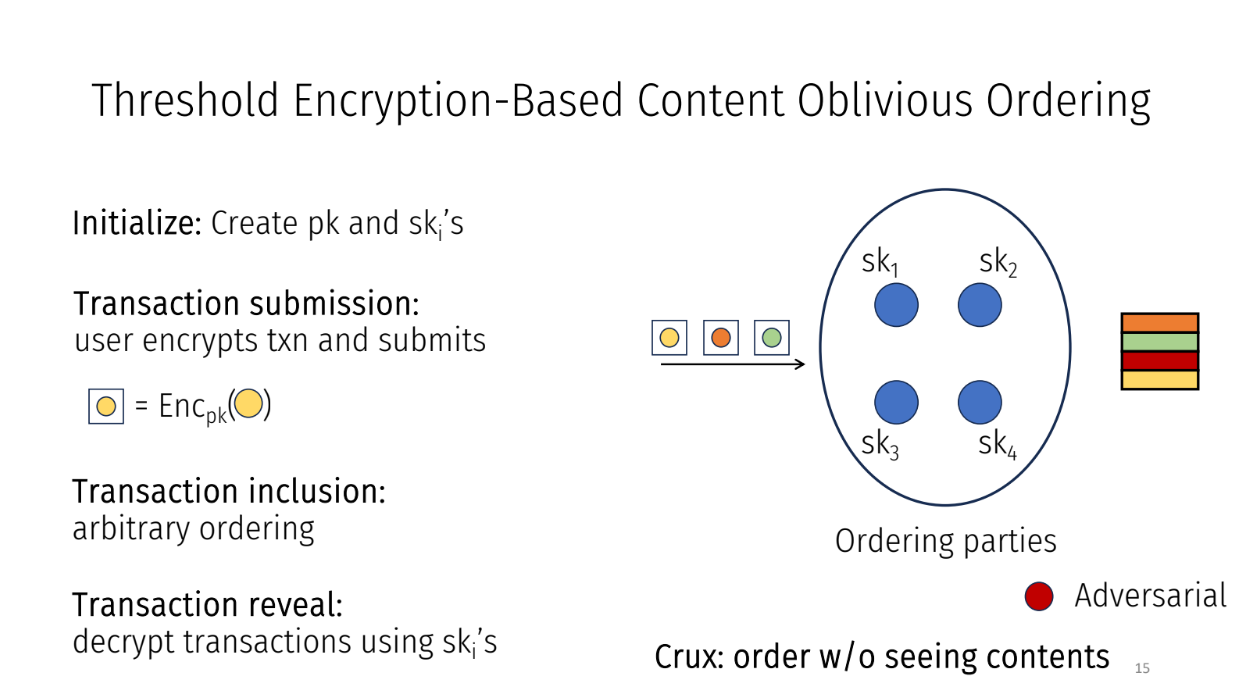
The framefork works as following :
- Initialization : Generate a public key and secret keys for each party in the system
- Transaction Submission : Users encrypt their transactions using the public key and submit them
- Ordering : Parties order the encrypted transactions however they want since they can't see the contents
- Revealing : Once ordered, parties decrypt the transactions using their secret keys
The idea is parties can't unfairly order transactions since they don't know what's inside them when ordering. Even if a bad transaction came earlier, it doesn't matter since contents were hidden.
Generalized Framework Capturing OPE protocols (8:00)


In general, protocols in this framework have :
- Initialization with public/private parameters
- Users submitting transactions
- Parties capturing metadata like transaction arrival times
- Transactions ordered based on metadata
- Optional revealing of contents after ordering
- A binding property which says that a transaction executed by the protocol is the one that is submitted to it
- We assume that between after ordering and before revealing, the state of the transaction does not change.
Impossibility for Order Policy Enforcement
Explanation (10:30)

For protocols in this framework, if there is a way for parties to reorder transactions and earn more profit, they will do it.
Let's say the original order of transactions is t1, t2, ..., tl. And for this order, the sequence tSeq gives parties the maximum profit u.
Then parties will output tSeq instead of following the protocol policy P. They will manipulate the order if they can profit more.

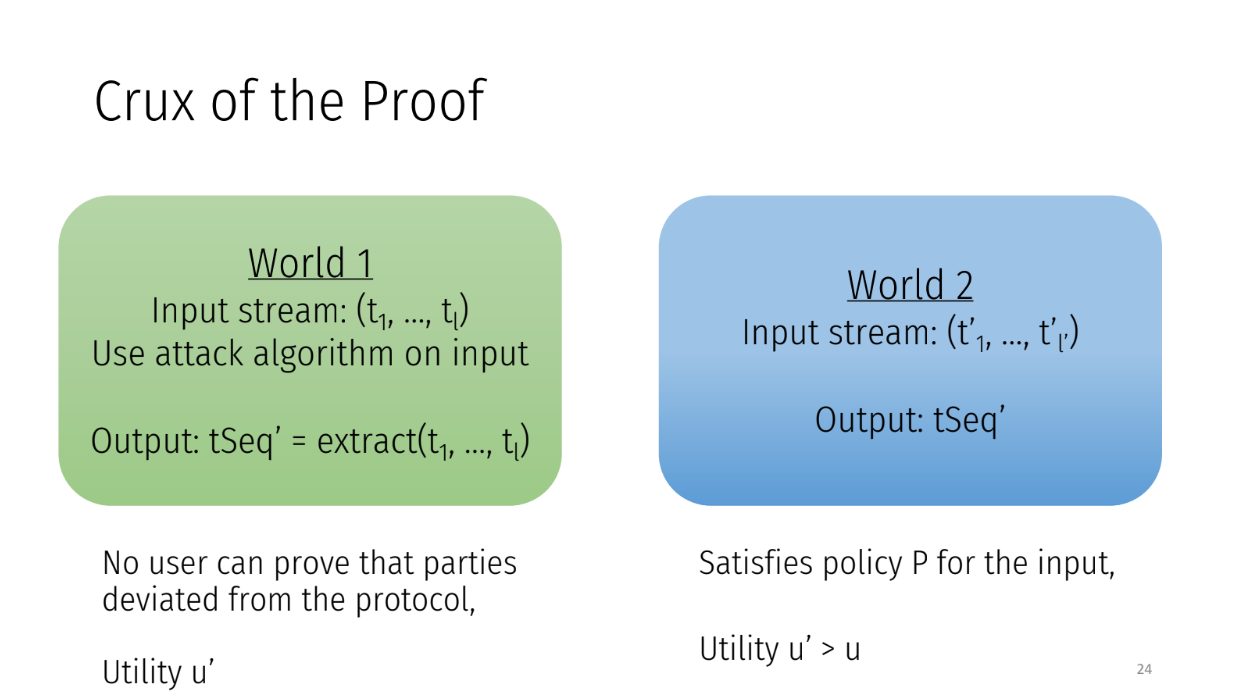
The attack works like:
- Parties reveal all transactions
- Run extraction functions to maximize profit
- Replay transactions in a different order TSEC'
- Publish new state with higher profit
This makes it look like a different input stream was submitted. Hence, no one can prove the attack happened. So rational parties will attack protocols in this framework if a profitable reorder exists.
How can order fairness be achieved when parties are rational ? That is the next part of the talk
Circumventing the impossibility
The two approaches (13:30)

- Require clients to stay online until their transaction is committed. This prevents attacks since parties can't see contents until after ordering.
- Relax the binding property : allow the executed transaction to differ from the submitted one, as long as rational parties still follow correct behavior.
In reality, keeping clients online is cumbersome. A better approach is relaxing binding
For example, say a client submits a "buy 50 tokens" transaction. The executed transaction could be "sell 50 tokens" instead. This is problematic, but if rational parties still follow correct behavior, binding only needs to hold for them. This is "rational binding"
From this, we can create a protocol using rational binding that prevents "sandwich attacks" in certain applications like automated market makers (AMMs).
Sandwich attacks on AMMs (16:00)

In an AMM, we trade one token for another:
- The exchange rate depends on token availability
- A user submits a transaction like "Buy Y tokens of A for X tokens of B"
- There is a slippage parameter S to allow for rate changes
Attackers exploit this by making transactions before and after the user's transaction. This reduces A's availability so the user gets a worse rate of 1-S times Y tokens. The attacker profits.
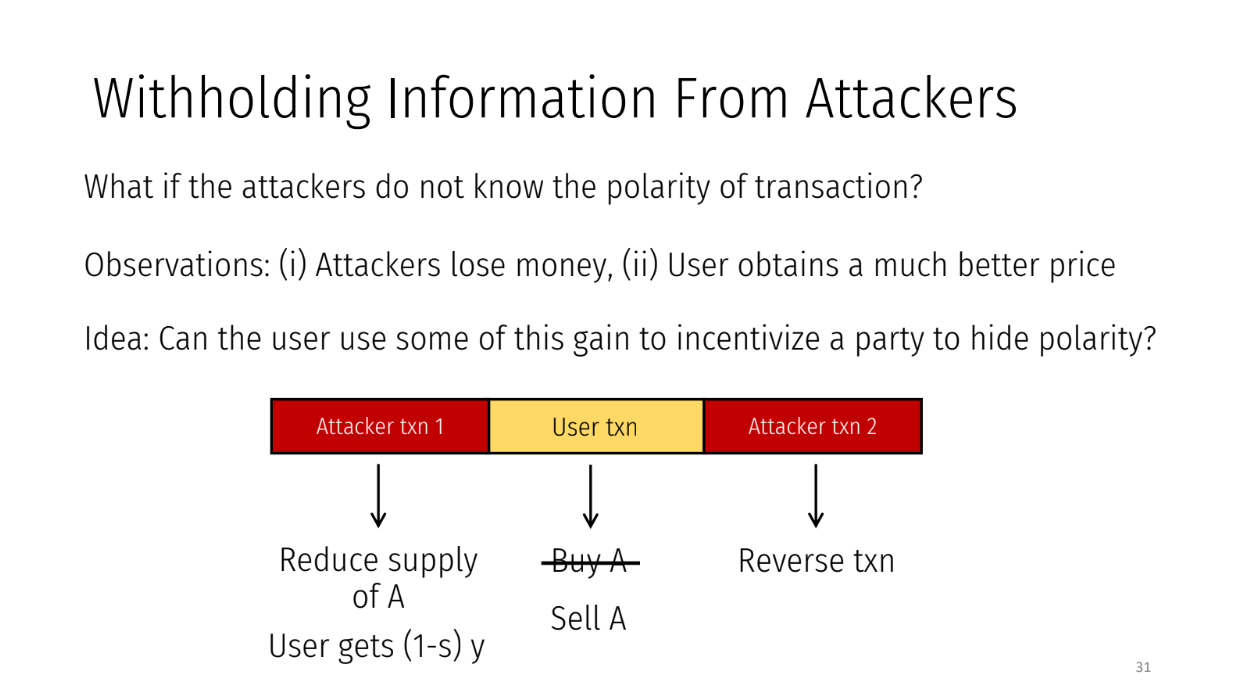
But how do attackers exploit slippage if transaction types (buy/sell) are hidden from them ?
If an attacker thinks his target is a buy order whereas this is a sell order, attackers would lose money by performing this attack and users would obtain a price that is much better than what they were initially anticipated.
Using an honest flipper to withhold information (18:30)


A "flipper" party sees the real transaction but hides it from other parties. This confuses them so they can't sandwich attack, and the flipper earns fees for its role.
Here is how it works with an honest flipper:
- User submits a "buy" transaction but flips it to "sell" with 50% probability before sharing with parties
- User shares real unsigned transaction with flipper
- Parties order the hidden transactions
- Flipper reveals the real transaction type after ordering
- This prevents sandwich attacks and guarantees correct execution
- Flipper earns fees when users get better prices from its help

To incentivize a rational flipper, it must be rewarded when its tricks help users, and must be penalized if it colludes and reveals info early
This uses rational binding to relax transaction binding while preventing attacks. Kartik is exploring caveats like insufficient user funds, but it's an interesting idea to stop attacks with rational parties.
Q&A
How do you discern that the flipper was honest after the events occur ? (22:00)
The flipper doesn't need to actually be honest. The flipper makes a commitment to the user to reveal the correct transaction type later. If they don't, the user can penalize the flipper.
Wouldn't you need to pay the flipper at least as much profit as they could make from a sandwich attack ? Otherwise they could just attack instead of helping (23:00)
By flipping the transaction, the user can gain more than the sandwich attack profit.
This extra profit can be shared with the flipper as payment. The flipper earns from the user, not from attacking.
Does the AMM need special integration with fle flipper ? (24:30)
Yes, after commitment the flipper must send an input to reveal the real transaction type. So some coordination is needed.
What prevents a malicious flipper from messing up transactions as a denial of service attack ? (25:00)
This is a limitation - a Byzantine flipper could attack and be penalized. They are relaxing transaction binding, so this attack is possible.
How a flipper is selected ? (25:45)
Kartik suggests who proposes a block could be the flipper. No specific selection method is defined.
Protected Order Flow
Fair Transaction Ordering in a Profit-Seeking World
This talk is about an ongoing research project called Protected Order Flow (PROF) that aims to enable fair ordering of transactions on blockchain networks like Ethereum.
The goal of PROF is to append bundles of transactions to blocks in a fair order, while still being compatible with existing systems like Flashbots.
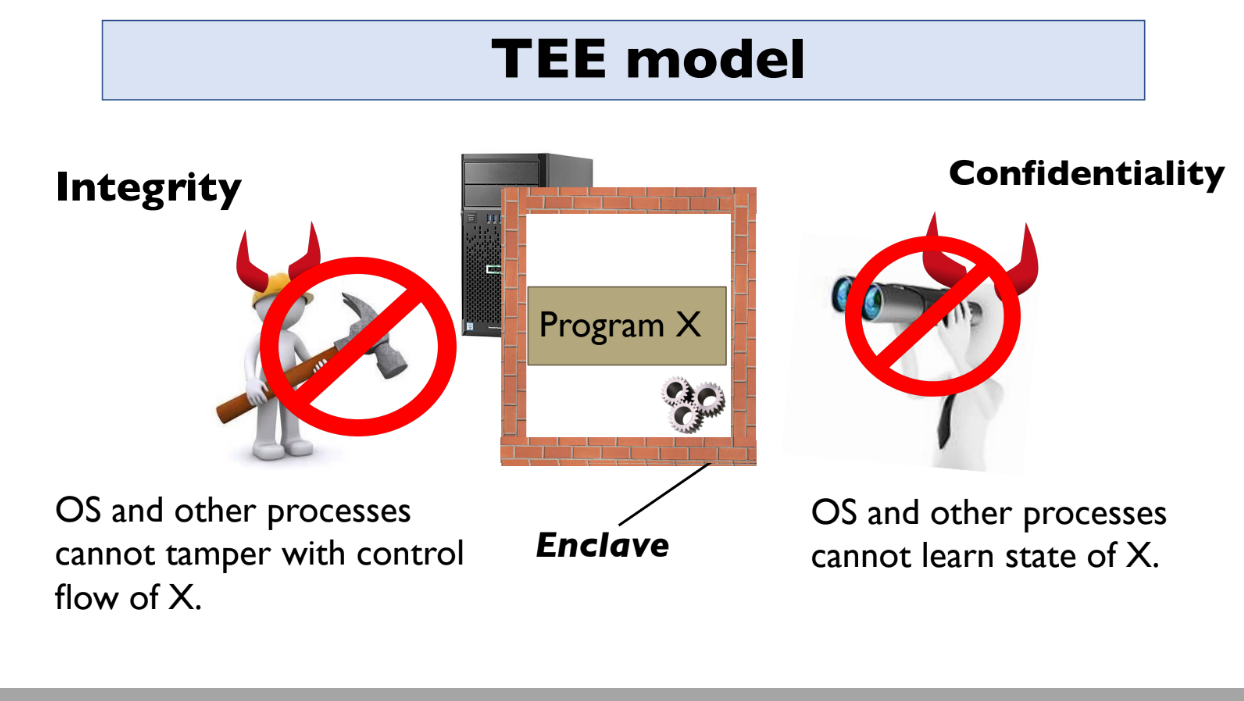
To do this, PROF leverages trusted execution environments (TEEs) like Intel SGX. TEEs allow you to run programs privately inside a protected environment.
The key properties of TEEs are:
- Integrity - no one can tamper with the program running inside
- Confidentiality - no one can see inside the program
- Attestation - TEEs can prove to users that they are running the correct program
Examples : AWS Nitro, Intel SGX, AMD SEV, ARM TrustZone
Using TEEs, PROF can run a program that securely orders transactions in a fair way and appends them to blocks.
This is different from previous systems because TEEs provide better trust guarantees. However, TEEs have some limitations around availability and side channel attacks.
TEEs for Block-Building and MEV supply chain
The MEV "supply chain" (4:00)
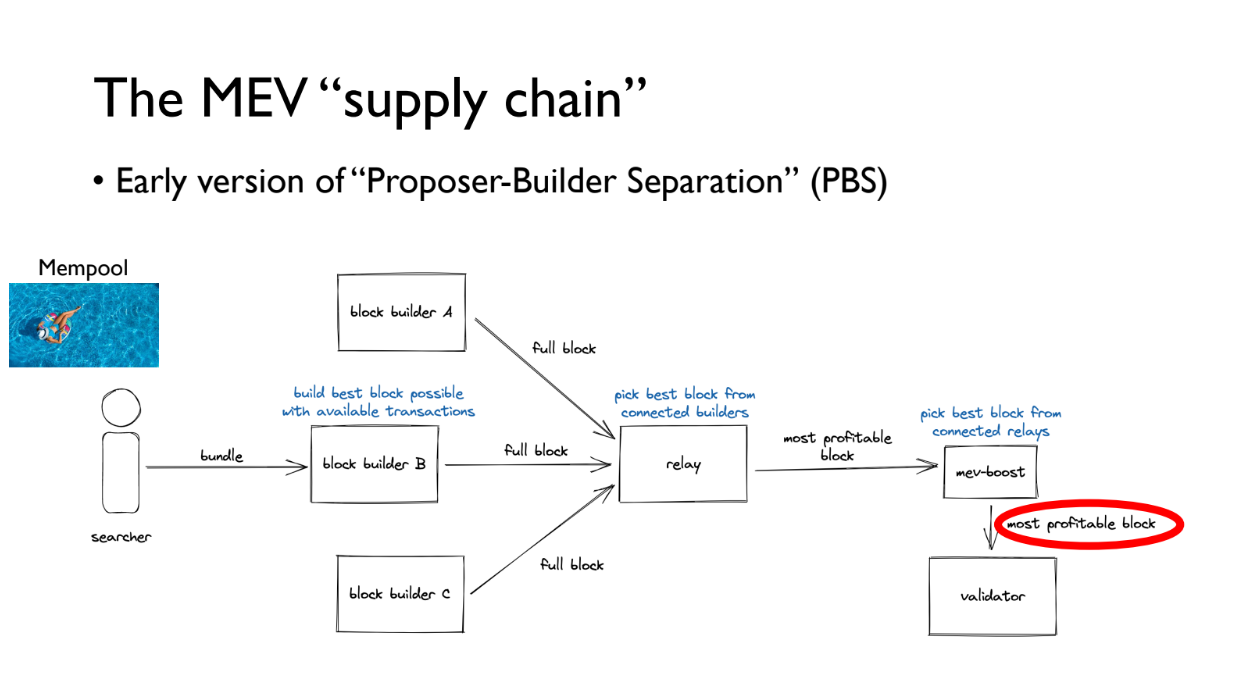

How the MEV supply chain works :
- There is a public mempool of transactions
- Searchers find profitable bundles of transactions and give them to block builders
- Block builders create full blocks and give them to relays
- Relays conduct auctions for the most profitable block in a fair way
- The most profitable block goes to the MEV-Boost plugin
- MEV-Boost makes sure validators only get the block after committing to include it
This system already uses TEE, as Flashbots runs its builder in a TEE. That said, there are plans to use them for PROF to allow appending a special bundle of fairly ordered, protected transactions to blocks to improve transaction ordering
Protected transaction alongside MEV-extraction (5:15)

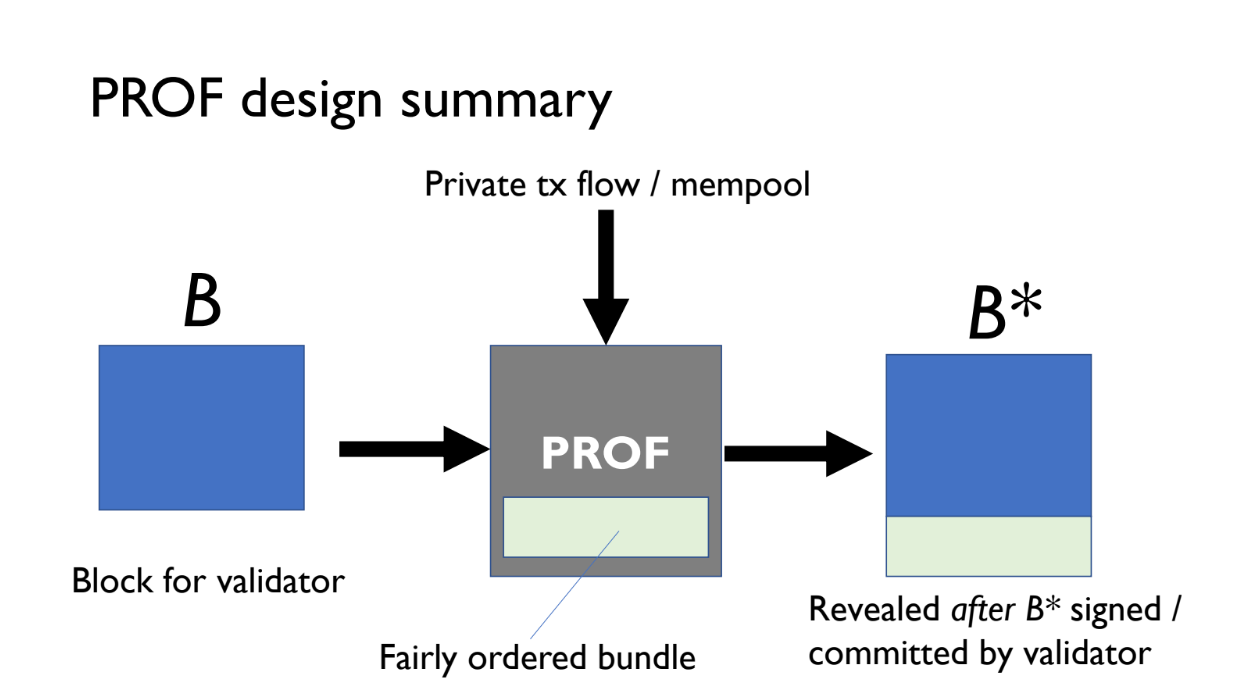
PROF creates two versions of a block:
- B = normal block
- B* = B plus an extra PROF bundle of transactions
Both B and B* are offered to the validator.
- B pays reward R
- B* pays reward R + epsilon (extra from PROF bundle fees)
The validator will choose B* since it pays more. The extra revenue epsilon comes from small fees paid by transactions in the PROF bundle
These PROF transactions are kept confidential using the TEE so no one can extract MEV from them
Why TEE ? (6:30)
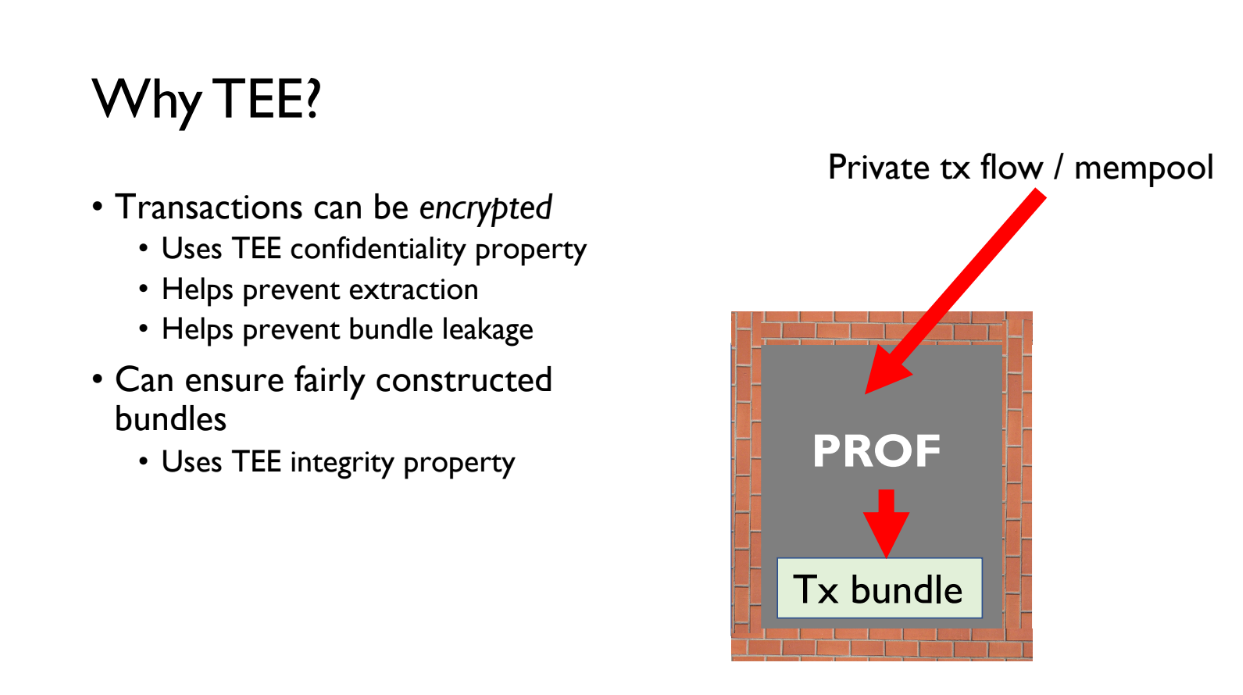
TEE provide privacy and integrity : transactions are encrypted inside PROF program, and it ensures bundle follows fair policy even if PROF runs untrusted hosts
PROF has 2 main components (7:30)
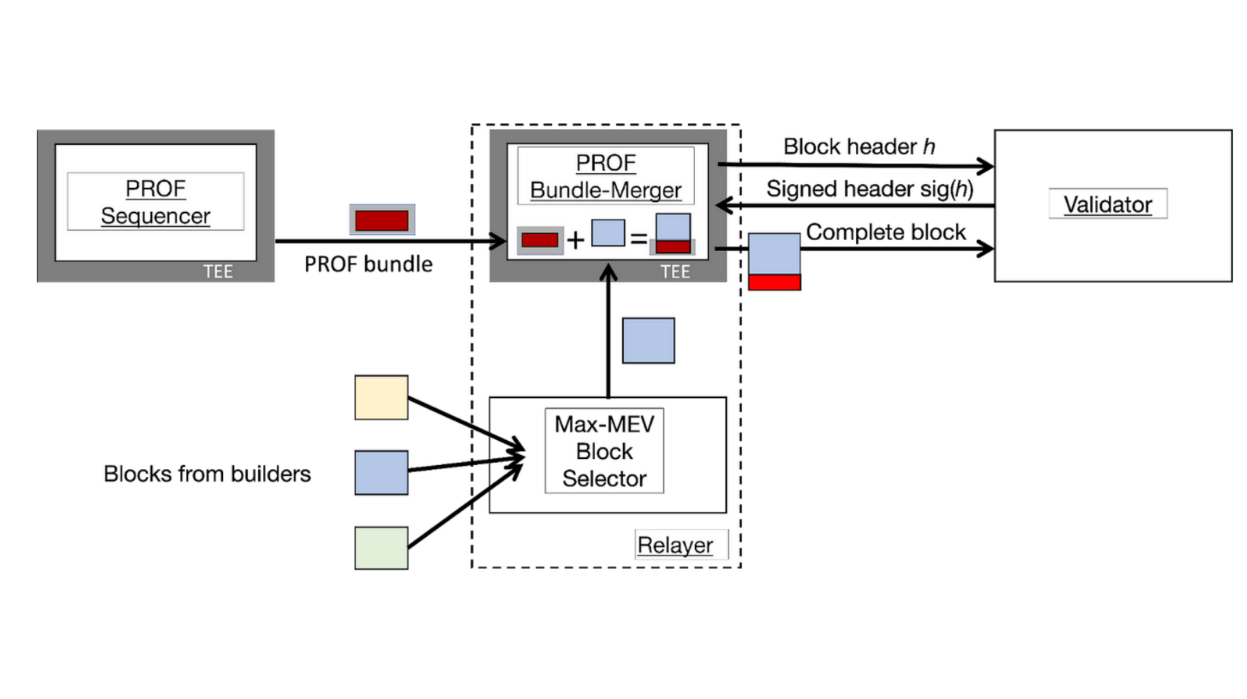
PROF Sequencer
- Forms bundles of transactions
- Can enforce different ordering policies
- There can be multiple Sequencers with different policies
- Sequencer encrypts the bundle to protect transactions
PROF Bundle Merger
- Runs inside a TEE at the relayer
- Relayer does its normal auction for blocks
- Winning block is sent to the Bundle Merger
- Merger appends encrypted bundle from Sequencer to the block
The relayer operates normally. The PROF components allow appending a special encrypted bundle with fair ordering to the winning block.
The Bundle Merger makes sure the full block is only released after validator commitment.
This design separates bundle creation from merging to allow flexible policies and leverages TEEs to keep transactions confidential.
Features
Fairly Ordered Transactions (9:15)

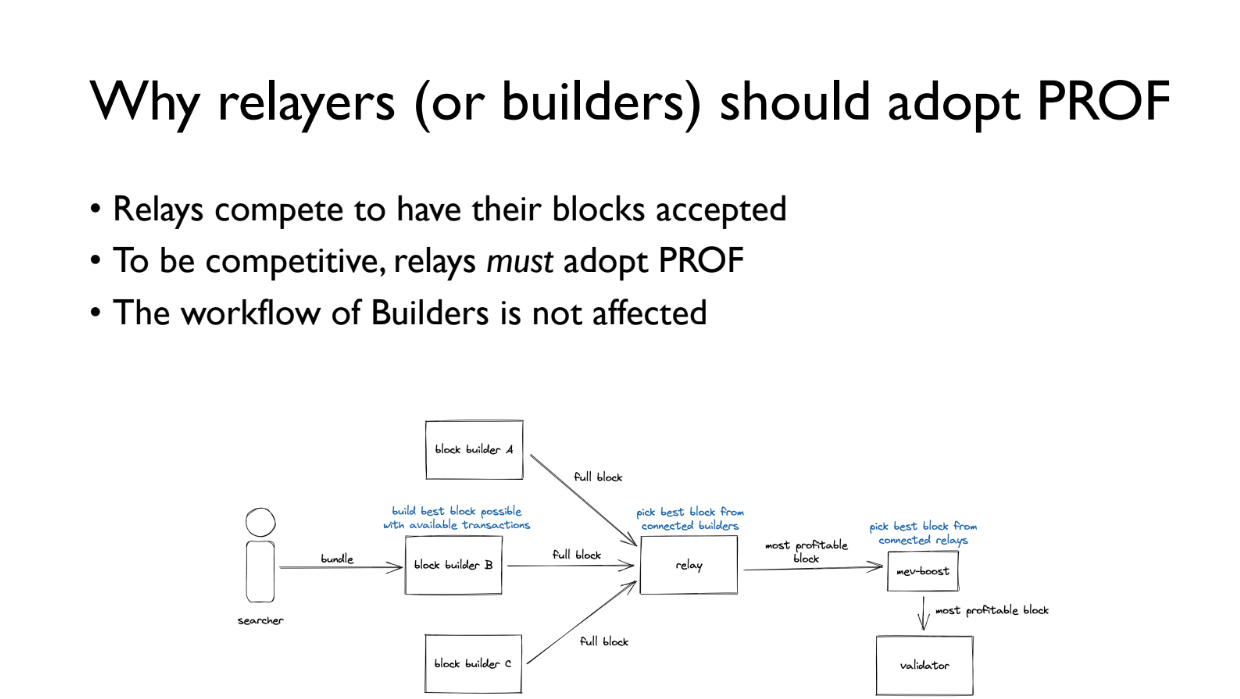
Validators profit more by including the PROF bundle, so are incentivized to use it
Relayers compete to have their blocks included by validators. By running PROF Bundle Merger, they can include extra PROF transactions to earn more fees and be chosen more often
Builders workflow is not affected. The PROF bundle is appended after their block, so their MEV extraction remains the same
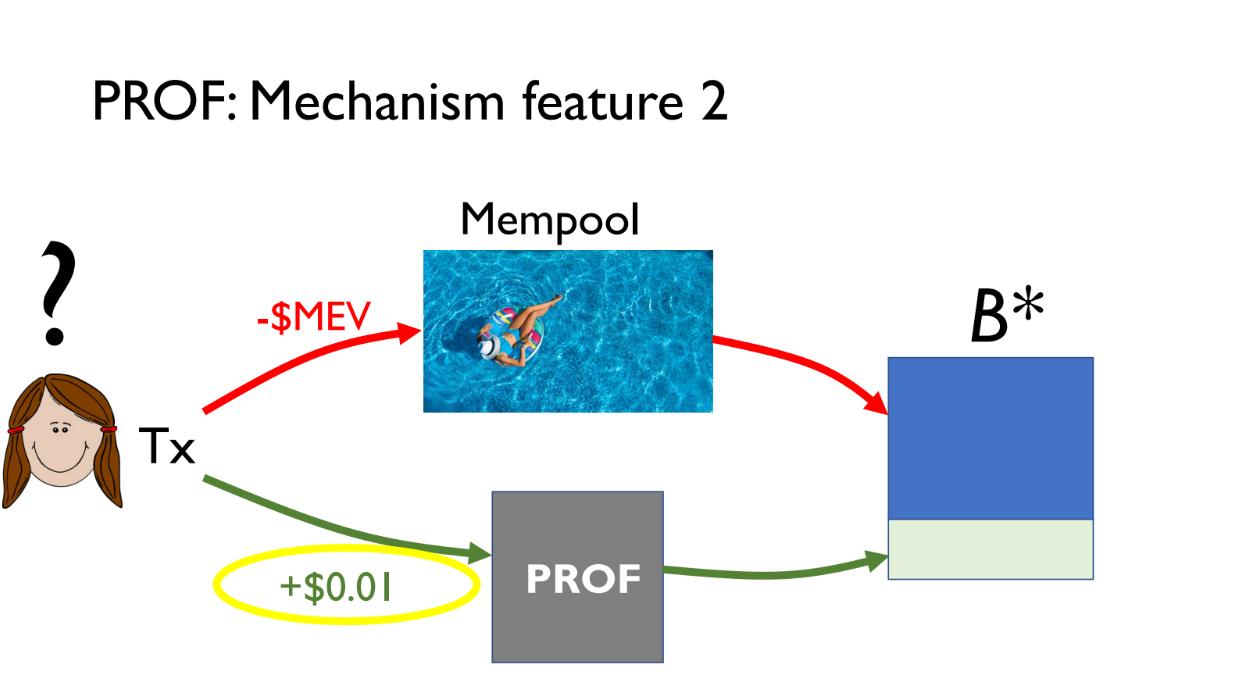
Users can either use public mempool and risk MEV extraction, or pay small fee to use PROF for fair ordering and transaction privacy
Things to work out (11:30)
PROF is designed so all parties benefit from adopting it. But there are still open questions to align everyone's incentives :

- Should PROF run at builders or relayers ? This implies tradeoffs around security and latency.
- How to handle PROF payments efficiently ?
- Can have multiple PROF Sequencers with different policies ?
We need more analysis needed of mechanism design and comparisons to other systems
The concerns (12:30)

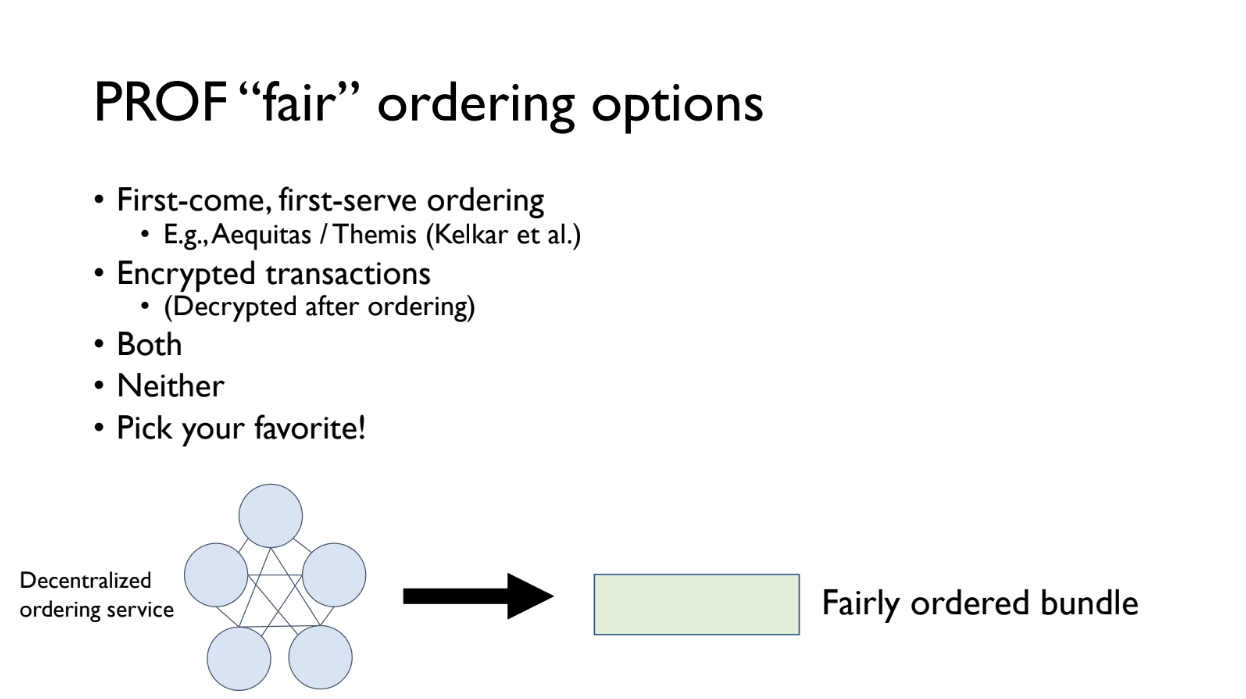
Kushal recommends reading the Prof blog post on the IC3 website to learn more details about the design and considerations. Two optential concerns are adressed :
- PROF can use different fair ordering schemes (First come first serve, Causal ordering where transactions stay private until on-chain, both or neither)
- Trusted execution environments (TEEs) have some limitations like availability failures and side channel attacks
Bothering with TEEs (13:30)


There are some serious limitations to using trusted execution environments (TEEs) like Intel SGX. There have been many security vulnerabilities and attacks against TEEs, especially around confidentiality (major attack in August 2022)
But without TEEs, user transactions have no protection and are public anyway. TEEs provide additional security on top of the status quo.
There are also ways to improve TEE security :
- New TEE designs and attack mitigations are being researched.
- The "Sting" framework is one approach to protect against TEE vulnerabilities
Q&A
Currently the relayer needs to build a full block and bid on it to participate. How PROF changes this and whether it should run at builders or relayers ? (15:00)
The bundle merging happens at the relayer in PROF's design. The builder workflow doesn't change - they make the same payment to validators.
The bid changes because the block now contains the additional PROF bundle, so validators see a higher bid.
There are different ways to share profits between validators, relayers and builders. TEEs can help enforce policies around profit sharing. The goal is for all parties to benefit in some way.
Appending a PROF bundle may increase latency, and higher latency generally means lower value. How to incentivize around block value and latency ? (16:15)
PROF bundle would only be used when latency costs are low towards the end of the bidding window. Relayers can run both normal and PROF bidding in parallel and take the more profitable block.
For high value low latency blocks, normal bidding would be used and PROF transactions would wait. This maximizes overall profitability.
Do you think that people would use this as a way to minimize tips (compared to using the public mempool) ? (18:30)
Using PROF still requires paying a tip, but protects against MEV extraction which is a risk with the public mempool.
Another person noted that Prof transactions go at the end of the block, so you lose priority. This may not work for arbitrage where you want priority.
Kushal agrees PROF is not for users who need top priority. It's for those okay having transactions at the bottom. Researchers are exploring inserting bundles earlier in the block.
Is there a potential design where you could submit private bundles that included transactions from the public mempool ? (20:00)
We could do that, but duplicate transactions get dropped when merging the bundle, so our sandwich may not succeed
Can relayers potentially colluding with validators to steal the PROF block from the TEE without publishing it ? (20:30)
If enough validators collude, attacks can't be prevented. But having an honest validator quorum would prevent this collusion.
How does the TEE know which validator's signatures it should release the PROF block to ? (22:00)
TEE runs something like a light client tracking validator sets and network state. Checkpointing and rollback protection help prevent network attacks on the TEE's view.